
Support Vector Machines
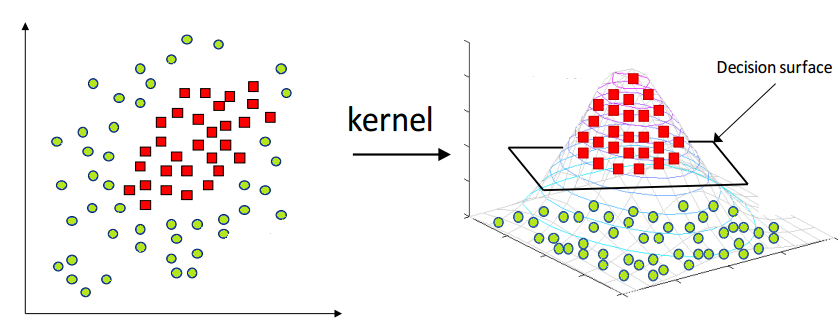
Support Vector Machines (or SVMs) are supervised machine learning models that can be used for classification or regression analysis. A support vector machine attempts to take data and split the data in such a way so that it values on one side of the split are classified one way and values on the other side of the split are classified differently. If you imagine a set of points on a graph, a split would be a line that splits the sets of points in two, where one set of points is one label and the other set of points is the other label. This idea can be extended into n-dimensional space and the split is a hyperplane. Below is what it could look like in 3-dimensional space, but this concept can be extended to many dimensions.
In this research into the effect of Covid-19 on food security, the SVM classifier used search data from the Google API and the survey data provided by the US Census/FRED. For the Google Search API data, the goal was to attempt to better understand the most important features of the dataset when it came to predicting the type of article. For the US Census data, the goal was to try to predict the effect of Covid-19 on different states given information on how people answered the survey and given the unemployment statistics for the food manufacturing and hospitality employment data.
Search Data Support Vector Machines
The first set of data used with the SVM classifier is the search data gathered and cleaned in previous steps. This data comes from two different sources and is combined here into one. The data comes from the Google Search API, where 4 different searches found 20+ articles each concerning the effect of different disasters on food security. In parallel, a set of research papers on the same topics were added to the mix to give a better set of predictions. Using this set of data, the SVM classifier is used to try to get a better understanding of how each disaster affects food security. Click on the link below to find out more.
More on predicting search data
Survey Data Support Vector Machines
The second set of data used with SVM classifier is the survey data gathered and cleaned in the previous steps. This data set comes from three different sources and is cleaned and combined into one for further processing. The data comes from the US Census, FRED (Federal Reserve Economic Data), and another 3rd party data source that collects information on Covid-19 lockdowns. Using this data, the regions are predicted using an ensemble of support vector machines (ensemble meaning more than one). Rather than trying to predict states, the research focused on determining whether certain regions were affected more than others.