
Naïve Bayes
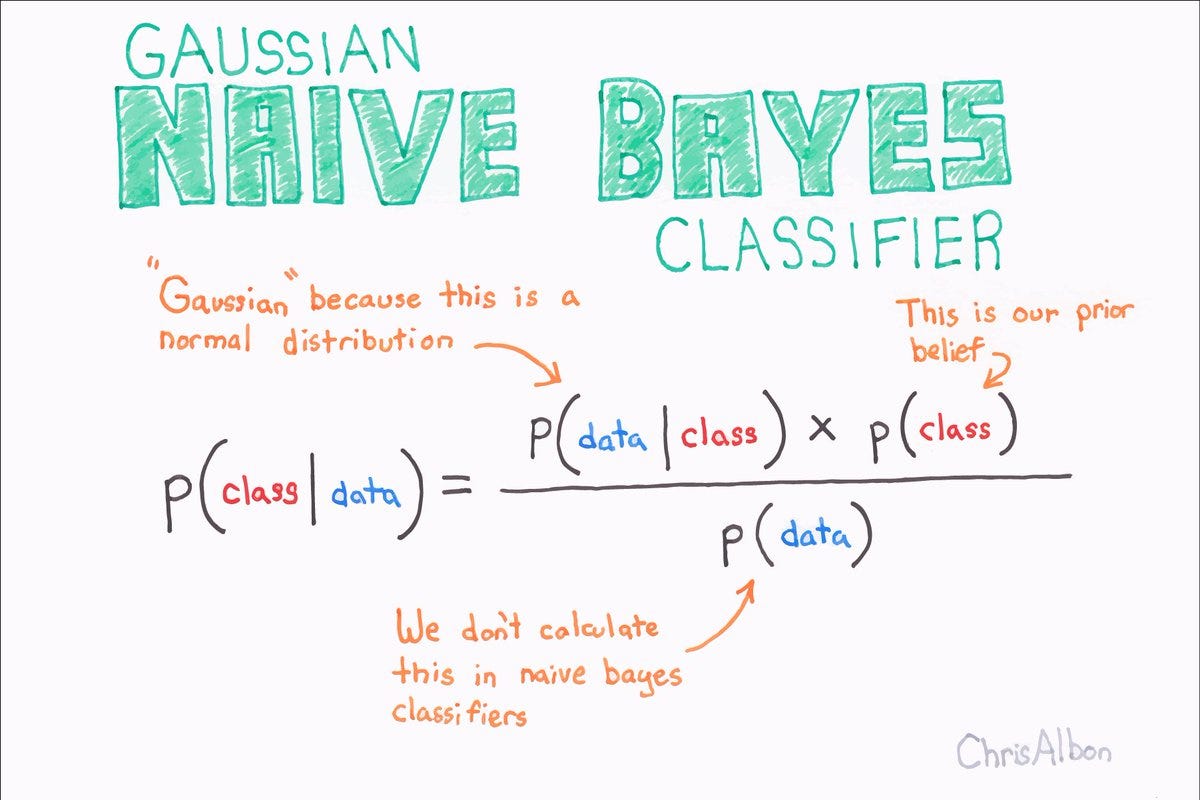
Naïve Bayes is a technique to construct classification models using the fundamentals of probability and statistics. Classification models are models that assign labels to sets of feature vectors. The main difference in Naïve Bayes is the assumption that each feature in the vector is independent of one another. The assumption is not usually true, since most features are correlated, but in making the assumption, the time and space complexity of the model is reduced. Further research on these naive assumptions has shown that despite these assumptions, many of these classifiers still work quite well on complex problems.
In this research into the effect of Covid-19 on food security, the Naïve Bayes classifier used the search data from the Google API and the survey data provided by the US Census/FRED. For the Google Search API data, the goal was to attempt to better understand the most important features of the dataset when it came to predicting the type of article. For the US Census data, the goal was to try to predict the effect of Covid-19 on different states given information on how people answered the survey and given the unemployment statistics for the food manufacturing and hospitality employment data.
Search Data Naïve Bayes
The first set of data used with the Naïve Bayes classifier is the search data gathered and cleaned in previous steps. This data comes from two different sources and is combined here into one. The data comes from the Google Search API, where 4 different searches found 20+ articles each concerning the effect of different disasters on food security. In parallel, a set of research papers on the same topics were added to the mix to give a better set of predictions. Using this set of data, the Naïve Bayes classifier is used to try to get a better understanding of how each disaster affects food security. Click on the link below to find out more.
More on predicting search data
Survey Data Naïve Bayes
The second set of data used with Naïve Bayes classifier is the survey data gathered and cleaned in the previous steps. This data set comes from three different sources and is cleaned and combined into one for further processing. The data comes from the US Census, FRED (Federal Reserve Economic Data), and another 3rd party data source that collects information on Covid-19 lockdowns. Using this data, the state associated with the each set of data is predicted. This is important in answering the question of whether different states were affected by Covid-19 when it comes to food security. An important note here is that this can only be done using Naïve Bayes since trying to predict 50 different labels are virtually impossible using something like decision trees, so there is already an advantage to using Naïve Bayes here.